Detectify后端团队的博客:
Detectify的后端团队已经使用Go有一些年头了,Go是我们提供为服务所选择的语言。我们认为Go是一个令人着迷的语言,而且它 被证明可以很好地为我们所用。它提供了一系列很棒的工具,比如接下来我们将要接触到的pprof。
然而,尽管Go表现地很好,我们发现其中一个微服务有一些很像内存泄漏的行为。
这篇文章将沿着我们如何发现这个问题、我们决策背后的思考过程、需要理解的细节和修复这个问题,一步一步探索下去。
它是如何开始的
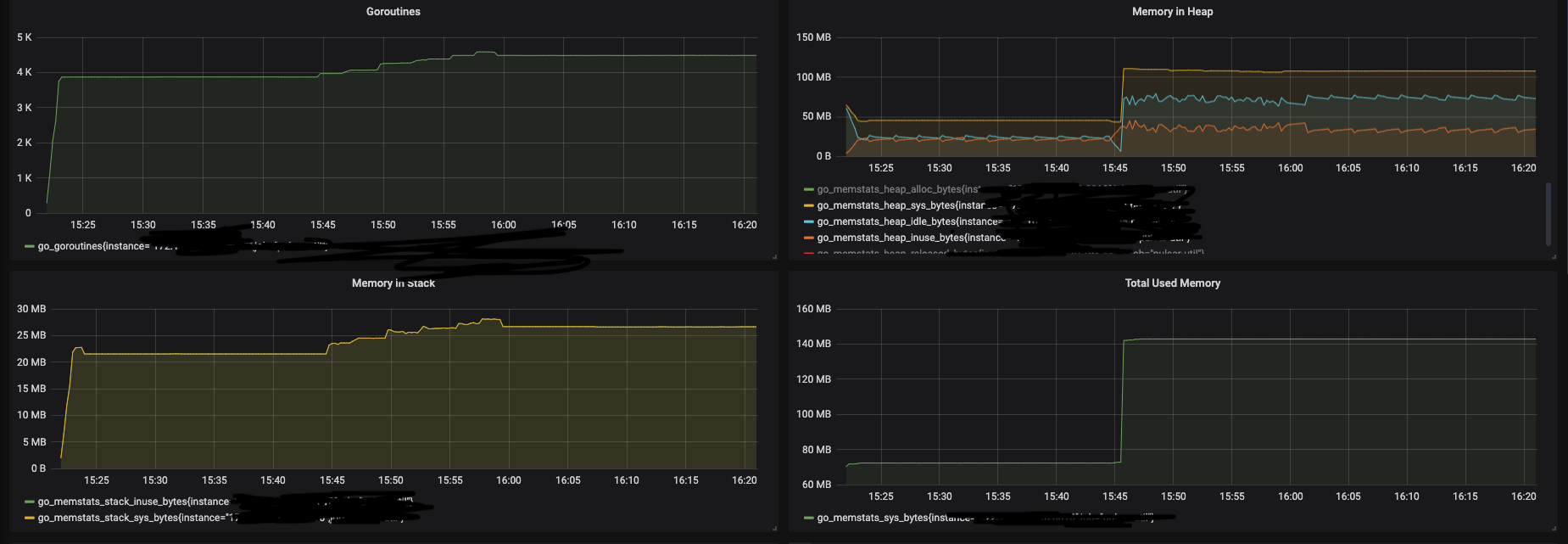
我们可以从监控系统中看到这个微服务的内存占用在逐渐累计并且不会下降,直到触发了OOM(Out of Memory) 的错误,或者我们 重启服务。
尽管Go有许多优秀的工具,但在这次调试过程中,我们想研究完整的内核转储,但是我们发现直到撰写本文时,使用pprof(包括 其他Go工具)并不能完成这个事。pprof有其局限性,但是它提供的功能依然有助于我们追寻此内存问题的根本原因。
Profiling Go with pprof
pprof是一个Go工具,用于可视化和分析profiling数据。它作用于CPU和内存的profiling,但是这里我们将不讨论CPU profiling。
在你的服务中设置pprof非常简单。你可以直接调用pprof函数,例如:pprof.WriteHeapProfile,或者你可以设置pprof http入口,我们发现后者更有趣。
对于后者,你只需要import pprof这个package,它将注册路由/debug/pprof。有了这个,你可以通过向这个endpoint发送GET请求 就能获取pprof数据,这个方式对于在容器中运行的环境非常方便。根据pprof的文档,在生产环境中使用它是安全的,因为pprof 几乎没有额外的开销。但是注意,pprof这个http endpoints不应该被公共网络访问,因为它包含了你服务的敏感数据。
以下是你需要添加到代码中的内容:
1
2
3
4import (
"net/http"
_ "net/http/pprof"
)
之后,你应该可以在/debug/pprof端点访问不同的pprof配置文件。例如,如果要使用heap profile,则可以执行以下操作
1
curl https://myservice/debug/pprof/heap > heap.out
该工具有多个内置配置文件,例如:
heap: 堆中对象内存分配的采样数据.
goroutine: 所有goroutine的堆栈追踪.
allocs: 内存分配的采样数据.
threadcreate: 系统线程的堆栈追踪.
block: 导致阻塞的堆栈追踪.
mutex: 堆栈中的锁状态信息.
你可以在pprof.go文件中找到有关它们的更多详细信息。
我们将会花费大部分时间在heap profile上。如果在heap pprof上你无法发现任何有用的信息,可以尝试下检查其他类型的pprof。 我们也检查了goroutine profile以确保没有任何goroutine泄露和内存泄漏。
我们在找什么?
在深入调查兔子洞之前,往回走一步然后搞清楚我们到底在找什么,这个很重要。换句话说,Go中会以什么方式出现内存泄漏( 或者其他形式的内存压力)?
Go是一个自带垃圾回收的语言,这个降低了开发者管理内存的压力,但是我们仍然需要谨慎那些不会被垃圾回收的内存。
在Go中,有几种方式会导致内存泄漏。大部分是由于:
- 创建子字符串和子切片
- 错误使用defer语法
- 没有关闭HTTP的response body(或者其他未关闭的资源)
- 被遗忘的goroutine
- 全局变量
你可从go101, vividcortex, hackernoon了解更多
现在我们对Go的内存泄漏已经有了大概的认知,此时你可能想说:”那么我就不需要任何profiling了,我可以直接看我的代码”
实际上,一个服务都会有超过10行以上的代码和许多结构体,尽管示例代码可以很明显地展示内存泄漏,但是在没有任何提示的情况 下搜索服务源代码就如同大海捞针,我们建议你在直接查看源码前使用pprof,这样你就可以找到一些问题所在的好线索。
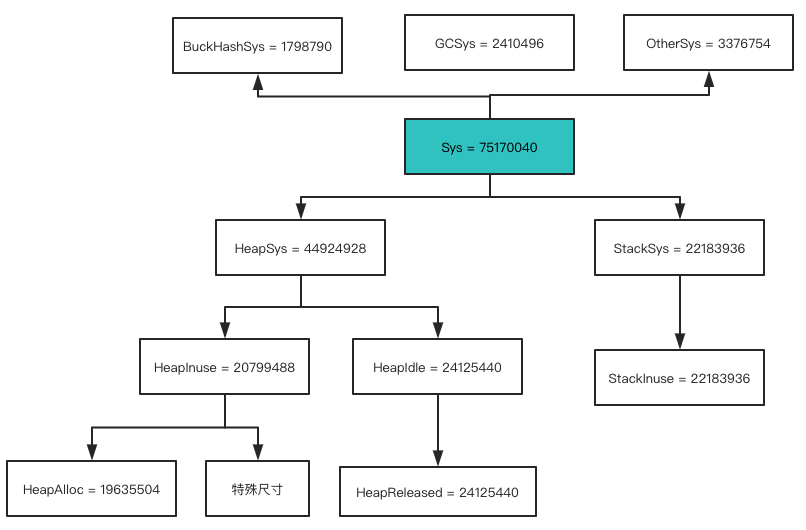
Heap profile总是一个很好的开端,因为heap是发生内存分配的地方。堆不是发生内存分配的唯一地方,某些内存分配也会发生 在栈中,但是接下来我们不会讨论内存管理系统的内部工作原理,你可以在文章末尾找到更多相关资源。
寻找内存泄漏
万事俱备,开始调试,我们开始查看服务的heap profile:
1
curl https://services/domain-service/debug/pprof/heap > heap.out
现在我们有了heap profile,接下来我们来分析它。运行下面的命令以开启命令行:
1
go tool pprof heap.out
命令行看起来是这样:

Type部分:inuse_space表示正在使用模式,它还可以是:
inuse_space: 表示pprof展示的是还未释放的内存占用空间
inuse_objects: 表示pprof展示的是还未释放的对象数量
alloc_space: 表示pprof展示的是所有内存占用空间,不管是否被释放
alloc_objects: 表示pprof展示的是所有对象数量,不管是否被释放
如果你想改变模式,可以执行:
1
go tool pprof -<mode> heap.out
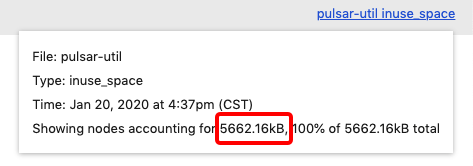
好的,现在回到提示符,最常见的命令是top,它显示了内存消耗最大的用户。这是我们得到的:

当我们看到这种情况时,我们的第一个想法就是pprof或监视系统出现了问题,因为我们稳定地看到400MB的内存消耗, 但是pprof报告的内存约为7MB。我们登录计算机检查docker stats,他们还是报告了400MB内存消耗。
pprof 怎么了?
这是其中一些术语的简要说明:
- flat:表示由函数本身分配的内存。
- cum:表示一个函数或者它下游调用的所有函数所分配的内存。
我们还在pprof提示符下运行了png命令,以生成调用及其内存消耗的图表。

在这一点上,要特别提到的是pprof还支持Web UI。您还可以通过运行以下命令在浏览器中查看所有数据:
1
go tool pprof -http=:8080 heap.out
通过上面的图,我们决定看一看 GetByAPEX 这个函数,因为从图表来看大量的内存压力由这个函数产生(尽管
最大是7M)。果然,我们发现了许多可能会导致内存压力的代码,比如大量使用 json.Unmarshal , 而且
还会向切片追加许多结构体。简单来说,GetByAPEX所做的就是从Elastic集群拉取一些数据,做一些转换,然后
将它们追加到切片中再返回它。
尽管如此,这不足以造成内存泄漏,它仅仅会导致内存压力,更不用说pprof中报告的7MB和我们在监控系统中看到的 相比并没有什么。
如果您正在运行Web UI,则可以转到“Source”选项卡以逐行检查带有内存消耗注释的源代码。在命令行中使用 list 命令 也可以做到这一点。它使用正则表达式作为输入,将过滤后的源码显示给你。因此,你可以在 top 显示最占用内存的关键 函数上使用 list 。
我们决定看看被分配的对象数量,这是我们得到的结果:

在看到上面的图片后,我们认为罪魁祸首是以某种方式将结构体追加到切片中,但是分析了代码后这里不可能导致内存泄漏,因为 没有其他代码去一直保持着引用这个切片,或者引用这个切片的子切片。
此时我们想到或许是这个Elastic库导致了内存泄漏,长话短说,在这里我们也没有 发现任何问题。
在pprof的范围之外会出问题吗?
我们开始认为我们应该查看完整的核心转储,或许在向Elastic集群发出请求的时候,某些连接和goroutine被hang住?所以
我们查看了goroutine profile:
1
2curl https://services/domain-service/debug/pprof/goroutine > goroutine.out
go tool pprof goroutine.out

一切都看起来很正常,没有异常的goroutine出现。我们也使用了netstat去检查服务容器的TCP连接的数量,也没有异常信息, 所有的TCP连接都被正常的关闭。我们发现了一些 idle 状态的连接,但是它们最终也被关闭了。
此时我们不得不面对现实,即这不是内存泄漏。那个函数造成许多内存压力,而且go的垃圾回收或者运行时也在消耗内存。 我们能做的只有将那个函数优化成流式数据,而不是将结构体保存在内存中。但同时,我们对这种奇怪的现象产生了兴趣, 我们开始重新研究Go的内存管理系统。
关于Go运行时,我们尝试了两件事:使用 runtime.GC 手动出发垃圾回收,然后调用 runtime/debug 的 FreeOSMemory。
它们都不起作用,但是我们感觉我们离罪魁祸首越来越近了。 因为我们发现一些仍然是 open 状态的 关于Go内存管理的issue, 其他人也遇到了Go运行时没有释放内存给操作系统的问题。FreeOSMemory 被认为是强制释放内存,但在我们看来它并没有生效。
我们发现Go非常依赖它分配的内存,这意味着在释放内存给操作系统之前,它将持有这些内存一段时间。如果你的应用有一个 内存消耗的峰值,然后又有至少5分钟的静默期,Go将会把内存释放给操作系统。在这之前Go将持有它,防止它需要这些内存的 时候又重新向操作系统申请。
这个听起来很好,但是我们发现5分钟后内存还是没有释放。所以我们决定做一个小实验,确认问题是否出在Go的运行时。我们 将重启应用,然后运行一个脚本,它会一段时间内请求大量数据(我们称这段时间的请求量为 x ),然后在发现一个内存峰值 的时候,我们会再多运行5秒钟然后停止。接下来,我们会重新跑这个脚本(没有5秒钟的等待期),这样我们去验证Go是否会 请求更多的内存,还是仅使用它持有的内存量。这是我们得到的结果:

实际上,Go并没有要求操作系统提供更多的内存,而是在使用它之前保留的内存。问题是5分钟规则未得到遵守, 运行时从未向操作系统释放内存。
现在我们可以确定这不是内存泄漏,但是它仍然是一个不好的表现,因为这样会浪费很多内存。
我们虽然发现了罪魁祸首,但是我们仍然感到沮丧,因为这是我们无法修复的问题,这是Go的运行时方式。我们最初的想法 是到这里停止下来,然后优化服务。但是随着我们继续深入研究,在Go仓库 发现了一些讨论Go内存管理方式变更的issue:
- runtime: mechanism for monitoring heap size
- runtime: scavenging doesn’t reduce reported RSS on darwin, may lead to OOMs on iOS
- runtime: provide way to disable MADV_FREE
- runtime: Go routine and writer memory not being released
事实证明,在Go1.12中,关于运行时通知操作系统可以回收未使用的内存的方式,发生了一些变化,在Go1.12之前,运行时
在未使用的内存上发送一个 MADV_DONTNEED 信号给操作系统,操作系统立刻回收这些内存页。从Go1.12开始,信号变成了
MADV_FREE,这会告诉操作系统如果需要的话可以回收这块不使用的内存,这也意味操作系统如果没有来自其他进程的内存压力
,它将永远不会这样做。
除非你有其他正在运行的服务并且也很消耗内存,否则RSS(常驻内存,基本上是该服务正在消耗的内存)将不会消失。
从这个Go仓库的issue上看,这个问题仅仅会出现在iOS系统,而不会在Linux上,但是我们在Linux上遇到了相同的问题。
然后我们发现在运行Go服务的时候使用GODEBUG=madvdontneed=1去强制运行时使用MADV_DONTNEED而不是
MADV_FREE。我们决定试一试!
首先,我们在/freememory中添加了一个新HTTP端点,该端点只会调用FreeOSMemory。 这样,我们可以检查它是否确实适用于新信号。这是我们得到的:

绿线(服务-a)是我们在14:13到14:14之间调用 /freememory 的线,您可以看到它实际上将几乎所有内容释放到了操作系统。 我们没有在services-b(黄线)上调用 /freememory,但是它显然遵守了5分钟规则,并且运行时最终释放了未使用的内存!
结论
要对编程语言的运行时如何运行以及它所经历的更改有所了解! Go是一门很棒的语言,提供了许多惊人的工具,例如pprof(一直以来都是正确的,并且没有显示任何内存泄漏的迹象)。 学习如何使用它并读取其输出是我们从此“错误”中学到的最有价值的技能,因此一定要检查一下!
我们一路发现的所有链接:
- Jonathan Levison on how he used pprof to debug a memory leak.
- [VIDEO] Memory leaks in Go and how they look like.
- Another memory leak debugging journey!
- How to optimize your code if it’s suffering from memory pressure, and also general tips on how the Go memory model works.
- How the Go garbage collector works.
- Go’s behavior on not releasing memory to the operating system.